Cadence开发出Tensilica NeuroEdge 130 AI协处理器 旨在为汽车神经处理单元提供更高的灵活性

据外媒报道,电子设计自动化软件公司Cadence开发出可配置协处理器Tensilica NeuroEdge 130 AI,旨在为汽车神经处理单元提供更高的灵活性。
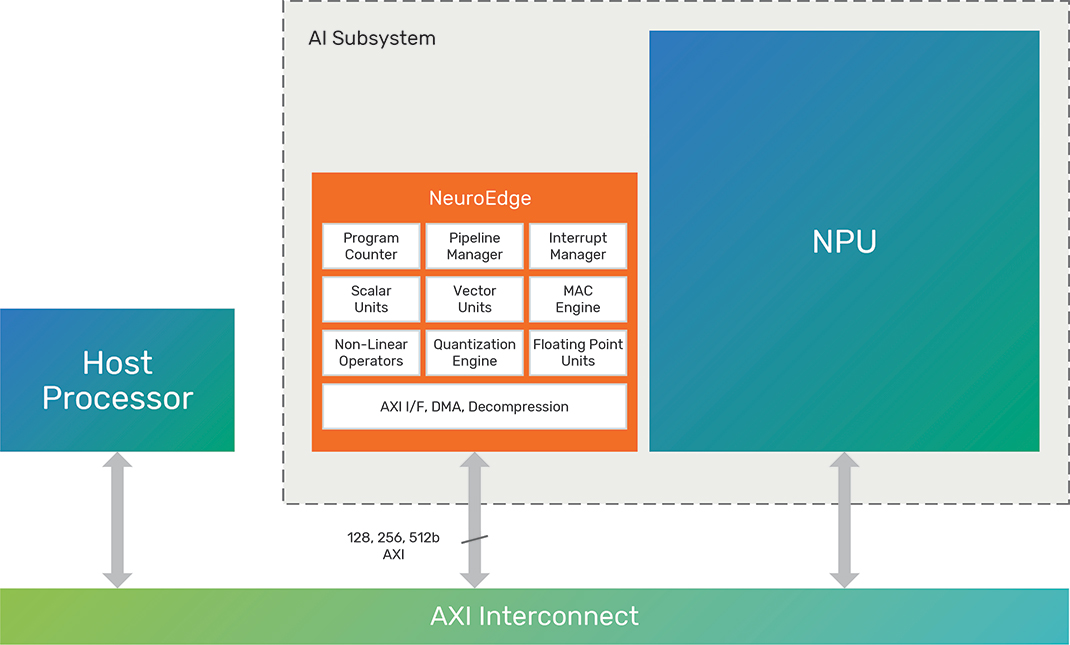
图片来源: Cadence
Tensilica NeuroEdge 130 AI协处理器(AICP)是一种新型处理器,旨在补充各种神经处理单元(NPU),用于高级汽车、消费电子、工业和移动SoC上的代理和物理AI网络。
该核心基于Tensilica Vision DSP系列成熟的架构,在不影响性能的情况下,可节省30%以上的面积,并降低20%以上的动态功耗和能耗。它还运行相同的软件、AI编译器和库。
Tensilica Xtensa基于VLIW的SIMD架构支持自定义扩展,从而能够与内部NPU兼容,从而相比其特定应用的前代产品提升端到端性能和效率。
它向作为控制处理器的NPU发出指令和命令,并采用优化指令来运行非NPU所需的最优任务,例如ReLU、S型函数和tanh。它使用512个8×8乘法累加器(MAC)单元发出512条指令,并包含一个用于为NPU提供数据的全新高带宽直接接口(HBDI)。
Cadence方面表示,目前正在与多家客户进行合作,包括Indie Semiconductor和Neuchips。Dream Chip也将Tensilica核心用于汽车设计。
“随着人工智能处理在自动驾驶汽车、机器人、无人机、工业自动化和医疗保健等物理AI应用中的快速普及,NPU正扮演着更为关键的角色,”Cambrian AI Research创始人兼首席分析师Karl Freund表示。“如今,NPU处理着大部分计算密集型的AI/ML工作负载,但大量非MAC层包含预处理和后处理任务,这些任务最好转移到专用处理器上。然而,当前的CPU、GPU和DSP解决方案需要权衡利弊,而业界需要一种低功耗、高性能的解决方案,该解决方案针对协同处理进行了优化,并能够满足未来快速发展的AI处理需求。”
“Cadence已利用Tensilica DSP验证了AI协处理器的用例。随着AI工作负载的转型和领域特定性的降低,我们的AI SoC和系统客户一直在寻求一款小巧高效的AI协处理器,以实现更高的PPA和面向未来的需求。”Cadence高级副总裁兼芯片解决方案事业部总经理Boyd Phelps表示:“秉承我们在IP创新方面的卓越成就,我们推出了一款专为特定应用而设计的全新处理器。Tensilica NeuroEdge 130 AICP旨在作为NPU的配套产品,提升了性能效率,以满足客户最苛刻的AI应用需求。”
“人工智能和计算机视觉在日益广泛的嵌入式应用中发挥着重要作用,”Edge AI and Vision Alliance创始人Jeff Bier表示。“但人工智能模型以及相关的预处理和后处理步骤正在快速发展;例如,如今许多开发者正在采用基于Transformer的多模态模型和基于LLM的人工智能代理。我们赞赏Cadence在灵活高效的处理器方面不断创新,这些创新是实现边缘人工智能和视觉广泛部署的关键。”
NeuroEdge 130 AICP由Cadence NeuroWeave™软件开发套件(SDK)支持,该套件是一个适用于所有Cadence AI IP的SDK。它使用张量虚拟机(TVM)堆栈来调整、优化和部署用于Cadence AI IP的人工智能模型。它还配备了一个轻量级的独立人工智能库,允许在新处理器上直接对人工智能层进行编程,并绕过某些编译器框架的潜在开销。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。