
火山引擎:智能辅助驾驶多模态数据湖最佳实践

随着辅助驾驶技术的快速发展,数据在推动算法迭代和场景优化中扮演着核心角色。数据飞轮理念强调高效的数据采集、处理和应用闭环,但在实际应用中,网联数据井喷、智能辅助驾驶多模态数据异构性处理和多团队协同等问题导致效率瓶颈。火山引擎通过全模态数据湖能力基座,旨在提升数据流转效率,降低存储成本,并加速算法训练。
2025年7月22日,火山引擎数据产品解决方案高级经理张伟亮在2025第八届智能辅助驾驶大会上表示:“数据飞轮在辅助驾驶领域至关重要,但面临高工程协同和极致数据处理效率挑战;火山引擎的全模态数据湖能力基座通过开源兼容、AI原生设计,实现数据高效流转,大力发掘潜在价值,让数据真正成为资产而不是隐性负债。”

张伟亮|火山引擎数据产品解决方案高级经理
以下为演讲内容整理:
智能辅助驾驶的数据飞轮趋势
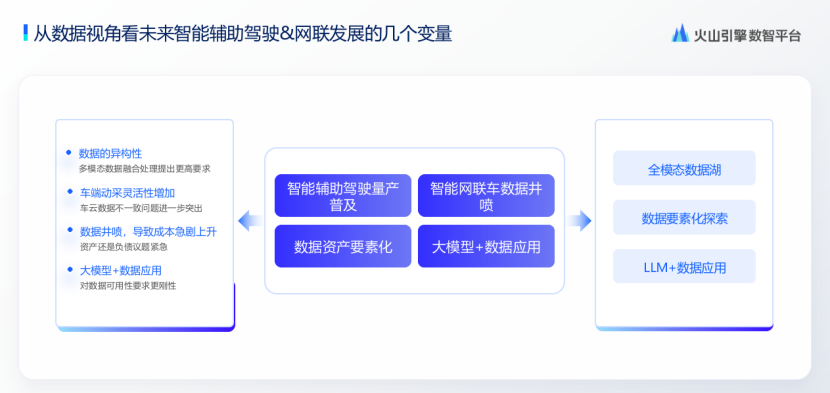
我们尝试从数据视角看一下智能辅助驾驶和网联发展的几个关键变量。首先是智能网联车数据井喷,随着车端数据采集方案的演进,车端数据采集采集频率越来越密集,智能网联车基本迈入了1hz时代,部分信号采集频率可以甚至可以到100hz,同时数采灵活性越来越高,很多时候无需OTA即可实现数据采集的变更,这就导致原始数据的shcema约束越来越弱,数据量的快速攀升、弱schema化、车云数据一致性等问题都导致云端网联大数据架构提出了严峻挑战。
第二个就是智能辅助驾驶的量产,在25年这个时间节点看,智能辅助驾驶量产基本变成行业的共识,但是来势之凶猛,公众关注的热切程度还是有些超乎意料,同时也让人充满敬畏之心。智能辅助驾驶原生是多模态数据处理场景,数据体量动辄到百P的量级。在这个体量的多模态数据处理压力下,对于底层处理引擎提出了极高的要求。同时数据上传、存储、处理、挖掘、应用带来的巨大成本压力,让客户越来越关注数据的直接应用价值,如不能直接证明价值,其实就很难说清已有的数据到底是资产还是隐性负债?
同时我们也在积极探索大模型代表的AI能力在数据全生命周期里面高效嵌入的场景。
图源:演讲嘉宾素材
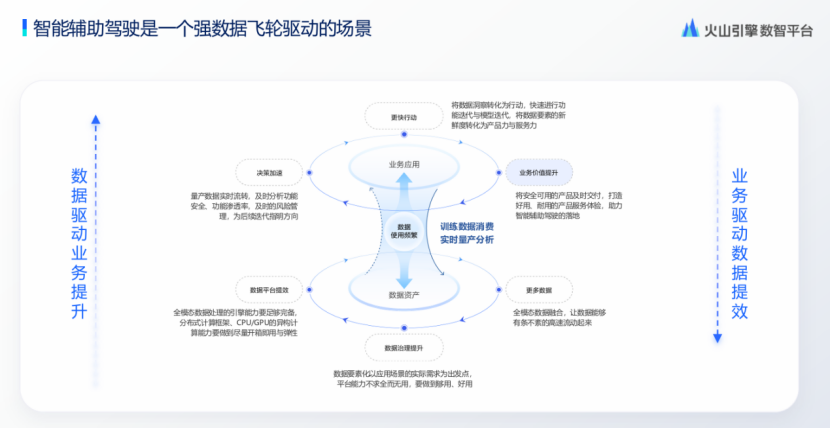
数据飞轮驱动辅助驾驶发展,但实际运行中存在研发效率低、版本混乱和合规风险等痛点。例如,在我们和客户沟通中,发现算法提出样本补充需求后,数据响应延迟中位数达T 3天,根源在于底层数据组织松散、元数据表达、服务能力的缺失。同时在多团队协作中,大数据技术栈差异,导致在数据翻译成本高,无形中也导致了效率的不必要损耗。
图源:演讲嘉宾素材
全模态数据湖能力基座设计
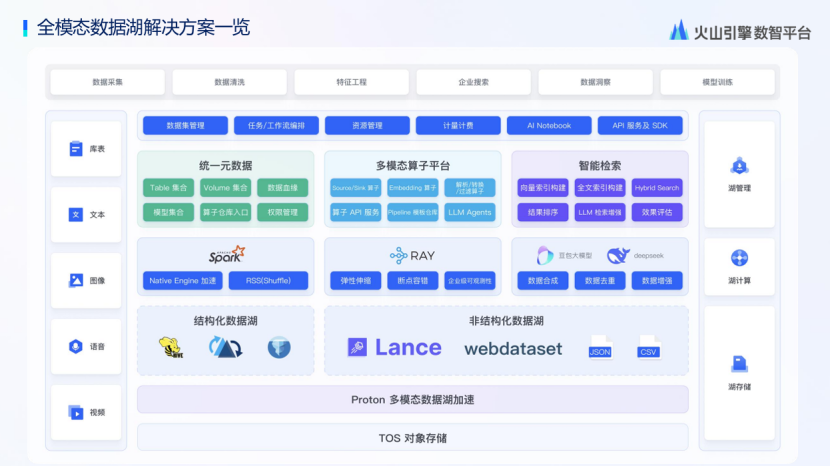
火山引擎采用“能力基座”而非“交钥匙方案”的核心逻辑,聚焦开放性和可插拔性设计,从根本上避免厂商锁定风险。其数据湖设计理念系统整合六大关键维度:开箱即用特性确保主流大数据组件预集成并持续迭代;开源兼容承诺与开源生态保持100%一致性,保障客户技术栈自由迁移;轻量运维通过Web化交互工具大幅降低管理负担;成本优化融合全托管架构、弹性伸缩及冷存归档策略;极致性能针对AI计算引擎内核深度调优;AI原生性为多模态场景创新设计。
在存储侧,除提供对象存储和高速文件系统等基础能力外,创新引入Lance数据湖格式强化多模态管理——通过Lance支持超大规模元数据描述,结合高级索引实现多模态数据秒级检索,并内置版本管理及Time Travel能力,显著提升非结构化数据的元数据管理效率,为辅助驾驶场景的复杂数据需求提供底层支撑。
图源:演讲嘉宾素材
计算侧深度整合Spark/Flink等大数据处理栈与Python生态框架(如Ray/Daft),通过Ray的分布式并行化能力显著降低算法团队技术栈改造成本,其在自动化标注等场景已验证可提升GPU利用率20%以上。管理能力构建包含元数据Catalog统一治理、跨多云支持体系,并开放API接口服务供客户自研系统对接,实现跨云数据平台的协同。
核心逻辑始终立足存储与计算基座层,通过开源兼容设计拥抱业务差异——例如在多模态场景采用Lance数据湖格式替代传统Parquet,凭借列存压缩优化减少30%存储空间占用,结合多维索引实现百倍级检索加速。能力基座完整覆盖数据资产轮与数据应用轮,在量产分析场景中通过Serverless Flink 实时湖仓架构将数据新鲜度压缩至分钟级,并借助弹性资源调度使响应效率提升50%,真正实现数据飞轮的高效运转。
图源:演讲嘉宾素材
实践案例分享
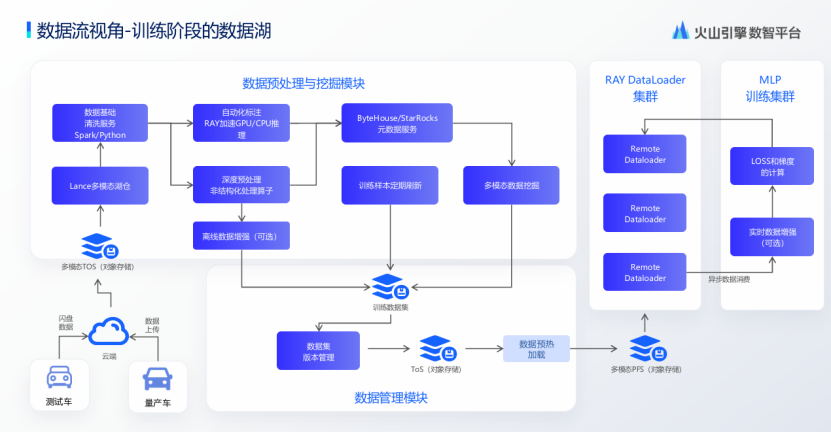
在某主机厂辅助驾驶项目合作中,火山引擎针对训练阶段样本刷新频繁、算子迭代导致的GPU利用率不足问题,创新实施Remote Dataloader解决方案——将传统耦合架构中的DataLoader处理模块拆分为独立EMR Ray集群,实现训练集群与数据预处理集群的异步解耦。改造后,当算法算子变更引发数据负载波动时,弹性CPU集群可动态承接预处理高峰,使H20训练卡利用率从瓶颈期的40%提升至稳定85%以上,单次训练迭代周期缩短50%。同步推进数据湖格式统一为Lance,依托其压缩算法优化及内置多维索引能力,在保障百PB级多模态数据高效访问的同时,显著降低云端存储成本20%并缓解跨集群数据消费时的带宽压力。
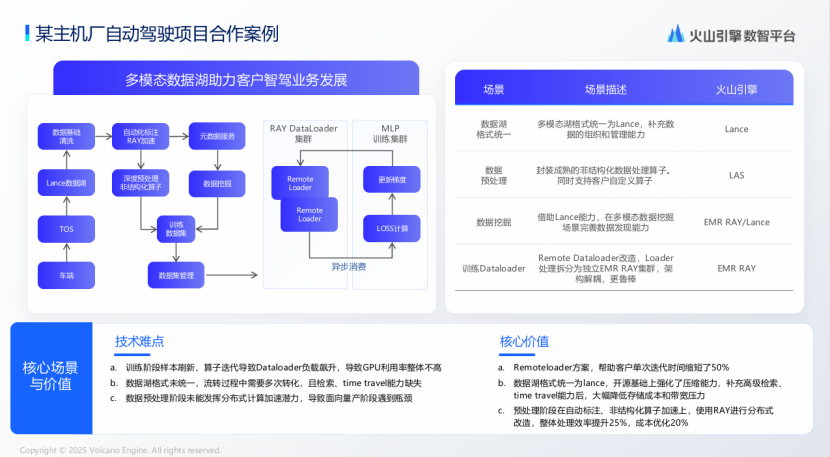
图源:演讲嘉宾素材
在火山引擎与某主机厂辅助驾驶项目的深度合作中,针对预处理阶段的自动化标注和非结构化算子处理瓶颈,创新采用Ray分布式计算框架进行改造——通过EMR Ray集群实现并行化调度,将CPU/GPU异构资源利用率提升20%以上,尤其在自动化标注推理任务中,批量处理非结构化数据的效率整体提升25%,同时降低20%的算力成本。另一量产分析项目则聚焦实时数据湖升级,通过Serverless Flink流处理引擎和Paimon Bytehouse湖仓架构,高效应对车云网关动态超长列数据挑战,支持每秒百MB级高吞吐写入,并确保数据新鲜度稳定在分钟级别,最终实现整体技术降本20%,为量产阶段的实时分析提供可靠支撑。
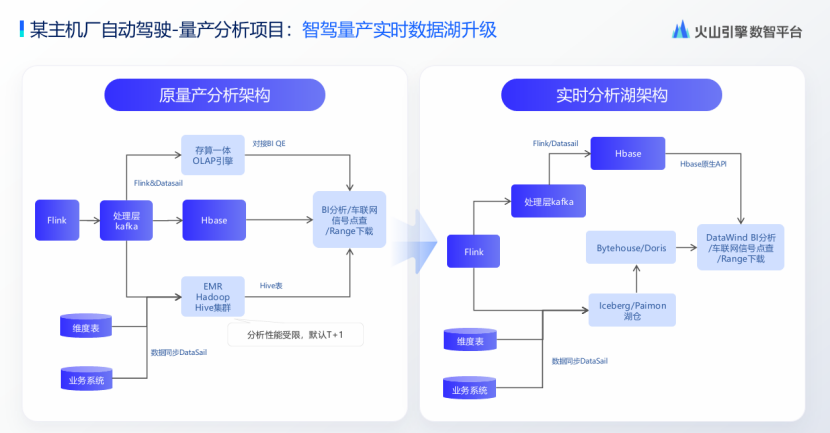
图源:演讲嘉宾素材
架构采用Serverless Flink实时链路、Paimon Bytehouse湖仓改造,数据新鲜度保持分钟级,整体技术降本20%。案例证明,多模态数据湖在样本挖掘、场景发现和成本控制上效果显著,例如长尾场景挖掘效率提升,避免“人力陷阱”。
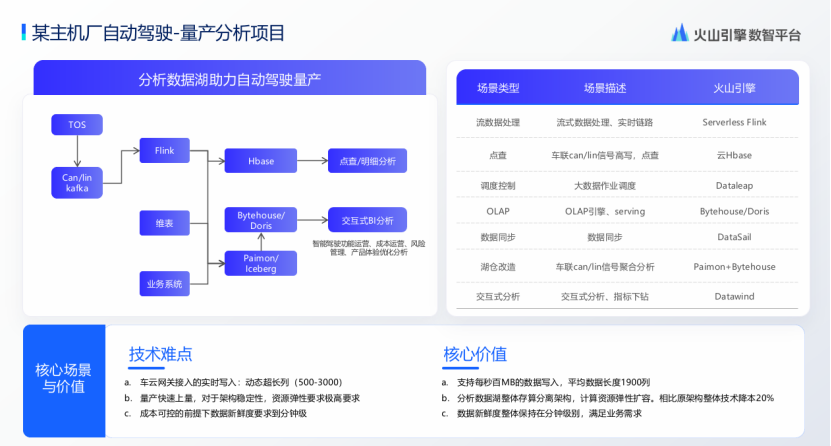
图源:演讲嘉宾素材
未来展望与挑战
未来需强化智驾 网联多模态湖仓基座性能,推进Ray Lance在量产分析场景落地,打造多模态实时数据湖。数据消费引领的要素化治理是核心方向,从训练和量产分析出发,确保数据转化为可量化资产,而非负债。
大模型(LLM)与数据应用结合,如Agents场景,将进一步释放价值,但挑战包括冷数据存储成本压力和合规响应时效性。技术路线迭代中,数据版本与训练版本关联需加强,避免“训练灾难”。持续优化方向是提升数据新鲜度、响应度和AI原生性,让企业数据收益更可观。
(以上内容来自于火山引擎数据产品解决方案高级经理张伟亮于2025年7月22日在2025第八届智能辅助驾驶大会上进行的发表的《智能辅助驾驶多模态数据湖最佳实践》主题演讲。)
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





