
中国研究人员发明全新动作好奇心算法 增强不确定环境下的自主导航

据外媒报道,在自主导航领域的一项突破性进展中,郑州大学一研究团队发现了一种新颖的路径规划优化方法,该方法在不确定的环境中表现出卓越的鲁棒性。这篇题为《基于行动好奇心的深度强化学习算法在非确定性环境中的路径规划(Action-Curiosity-Based Deep Reinforcement Learning Algorithm for Path Planning in a Nondeterministic Environment)》的研究论文于6月3日发表,代表了人工智能与实际应用(尤其侧重于自动驾驶汽车)融合的重大飞跃。
图片来源:Junxiao Xue et al.
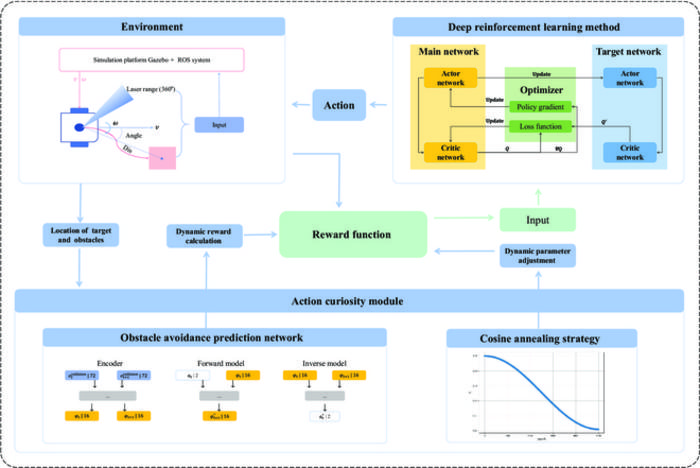
优化自动驾驶汽车路径规划的过程充满挑战,尤其是在这些车辆必须应对不可预测的交通状况时。随着人工智能技术的发展,研究人员正在积极探索各种策略,以提高这些系统的效率和可靠性。新开发的优化框架包含三个关键组件:环境模块、深度强化学习模块和创新的行动好奇心模块。
该团队将配备精密360度LiDAR传感器的TurtleBot3 Waffle机器人置于逼真的仿真平台中,并在四种不同的场景中测试了他们的方法。这些测试涵盖了从简单的静态障碍赛道到以动态和不可预测的移动障碍物为特征的极其复杂的情况。令人印象深刻的是,他们的方法相对于几种最先进的基准算法展现了显著的改进。关键性能指标表明,收敛速度、训练时长、路径规划成功率以及智能体获得的平均奖励均有显著提升。
该方法的核心是深度强化学习的原理,这是一种使智能体能够通过与动态环境的实时交互来学习最佳行为的范式。然而,传统的强化学习技术经常遇到诸如收敛速度缓慢和学习效率不理想等障碍。为了克服这些缺点,该团队引入了动作好奇心模块,该模块旨在增强智能体的学习效率,并鼓励它们探索环境以满足其与生俱来的好奇心。
这一创新的好奇心模块为代理的学习动态带来了范式转变。它激励代理专注于中等难度的状态,从而在探索全新状态和利用已有奖励行为之间保持微妙的平衡。行动好奇心模块通过集成障碍感知预测网络扩展了先前的内在好奇心模型。该网络根据与障碍相关的预测误差动态计算好奇心奖励,有效地引导代理专注于能够同时优化学习和探索效率的状态。
至关重要的是,该团队还意识到在训练后期过度探索可能会导致性能下降。为了应对这一风险,他们采用了余弦退火策略(cosine annealing strategy),这是一种系统地随时间调整好奇心奖励权重的技术。这种渐进式调整至关重要,因为它可以稳定训练过程,促进代理学习策略更可靠地收敛。
随着自主导航动态的不断发展,这项研究为未来路径规划策略的改进铺平了道路。团队设想整合先进的运动预测技术,这将显著提升其方法对高度动态和随机环境的适应性。这些进步有望弥合实验成功与实际应用之间的差距,最终有助于开发更安全、更可靠的自动驾驶系统。
这项研究的意义远远超出了学术研究的范畴。随着自动驾驶技术的进步,增强路径规划算法将在确保自动驾驶汽车在实际条件下行驶的安全性和效率方面发挥关键作用。通过利用复杂的强化学习策略并秉持好奇心驱动的方法,研究人员不仅正在应对现有的挑战,而且还在为人工智能和机器学习在交通运输领域应用的更广泛讨论做出贡献。
总而言之,基于行动好奇心的深度强化学习算法代表了自主导航领域的一项关键创新。通过应对非确定性环境的复杂性,该方法有望彻底改变自动驾驶汽车在不可预测环境中的运行方式。随着研究人员不断完善这些算法并探索其应用,自动驾驶技术的未来前景愈加光明,为智能交通系统的新时代奠定了基础。
研究界对这种优化方法的潜在应用仍然充满期待,它可能为未来自主系统的发展奠定基础。随着研究与合作的不断推进,能够在复杂环境中安全高效导航的全自动驾驶汽车的征程将越来越近,最终将迎来一个技术与交通和谐共存的未来。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





