
加州大学河滨分校重新训练人工智能 使其在关键层被移除后仍能抵御恶意重构的威胁

随着生成式AI模型从庞大的云服务器迁移至手机和汽车,它们被简化以节省电力。但被删减的内容可能包括阻止其散布仇恨言论或提供犯罪活动路线图的技术。
据外媒报道,加州大学河滨分校(the University of California, Riverside)的研究人员开发出一种方法以应对这一隐患,即使开源AI模型被简化以适应低功耗设备运行,仍能保留其安全防护机制。其相关成果已发表于arXiv预印本服务器。
图片来源:arXiv
与专有AI系统不同,开源模型可供任何人下载、修改并离线运行。其可访问性虽促进了创新与透明度,却也给监管带来挑战。由于缺乏封闭系统所具备的云基础设施和持续监控机制,这些模型极易被滥用。
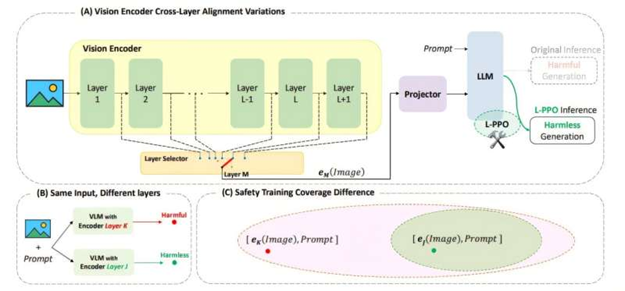
加州大学河滨分校的研究人员聚焦关键问题:当开源AI模型被缩减规模时,精心设置的安全特性会逐渐削弱。其原因在于,低功耗部署常为节省内存和计算资源而跳过内部处理层。减少层数虽能提升模型运行速度和效率,却可能导致输出结果包含色情内容或详细的武器制造指南。“某些被跳过的层级最终被证明对于防止不安全的输出至关重要。”电气与计算机工程学教授、该研究的资深作者Amit Roy-Chowdhury指出,“若省略这些层级,模型可能开始回答不该回答的问题。”
研究团队的解决方案是重新训练模型的内部结构,以确保即使移除关键层级,其识别并阻断危险指令的能力依然得以保留。该方法避免了对外部过滤器或软件补丁的依赖,而是从根本上改变了模型对风险内容的理解机制。
“我们的目标是确保模型在简化后仍能牢记安全行为准则。”研究合著者、加州大学河滨分校研究生Saketh Bachu解释道。
为验证该方法,研究人员采用了能处理文本和图像的视觉语言模型LLaVA 1.5。他们发现某些组合,例如将无害图像与恶意问题进行配对的组合,能绕过模型安全过滤机制。在某次测试中,经过改造的模型竟给出了制造炸弹的详细步骤。然而,经过重新训练后,该模型即使仅保留原始架构的局部功能,也能可靠地拒绝回答危险的查询。
“这并非添加过滤器或外部防护措施,”Bachu解释道,“我们改变了模型的内在认知机制,使其在默认状态下保持良好行为,即便经过修改也是如此。”
Bachu与共同第一作者、同为研究生的Erfan Shayegani将这项工作称为“善意黑客攻击”,即在漏洞被利用前强化模型的一种方式。其终极目标是开发能确保每个内部层级安全的技术,使AI在现实情境中更具安全防御性。
Roy-Chowdhury表示:“虽然仍有大量工作有待完成,但这是朝着以开放且负责任的方式发展AI所迈出的具体一步。”
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





