
中国研究人员发明新型机器人眼球 有望增强具身人工智能的视觉感知能力

具身人工智能(AI)系统是一种机器人代理,它依靠机器学习算法来感知周围环境、规划并执行动作。这些系统的关键组成部分是视觉感知模块,该模块使系统能够分析摄像头捕捉的图像并进行解读。
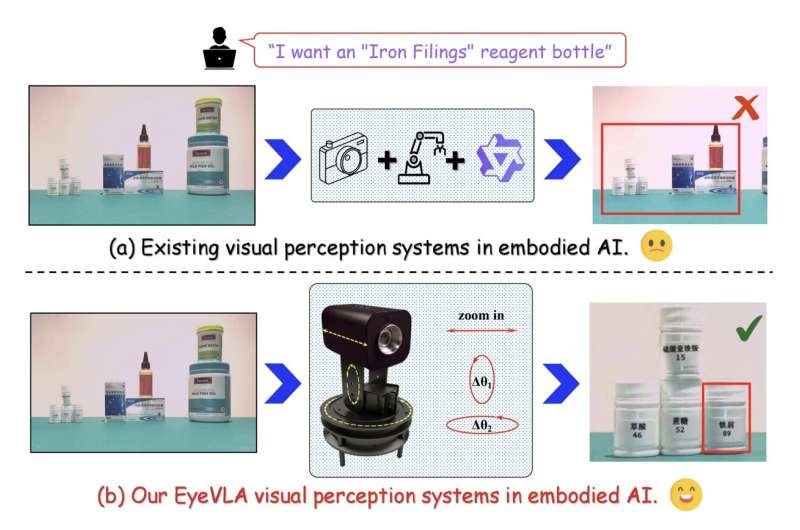
目前大多数用于具身AI代理的视觉感知模块都依赖于RGB-D摄像头,这种设备可以同时捕捉彩色(RGB)图像和深度(D)信息。然而,在大多数情况下,这些摄像头固定在机器人上,位置固定,这限制了它们在动态复杂环境中检测变化的能力。
图片来源:arXiv (2025)
据外媒报道,上海交通大学、中国科学院和大连理工大学的研究人员近期开发了一种受人眼启发的新型机器人系统,该系统能够旋转和放大,无需额外的传感器或更昂贵的摄像头即可获取物体的清晰图像。这款名为EyeVLA的机器人眼球已发表在arXiv预印本服务器上。
研究人员Jiashu Yang、Yifan Han及其同事在论文中写道:“现有的视觉模型和固定式RGB-D相机系统从根本上无法兼顾广域覆盖和精细细节获取,这严重限制了它们在开放世界机器人应用中的效能。为了解决这个问题,我们提出了 EyeVLA,这是一款用于主动视觉感知的机器人眼球,能够根据指令采取主动行动,从而在广阔的空间范围内清晰地观察精细的目标物体和详细信息。”
与以往许多用于视觉感知的机器人系统不同,这些研究人员开发的眼球状系统可以旋转自身并放大,从而更清晰地捕捉周围环境中的特定元素。此外,该团队还创建了机器学习模型,使机器人眼球能够处理用户的指令并相应地改变视角。
此次开发的模型通过强化学习进行训练,将摄像头的运动转换为“动作标记”,并像其他模型预测单词或特征图像一样规划其未来的动作。这些模型还会在物体周围放置二维方框,以引导系统关注特定的感兴趣区域。
“EyeVLA将动作行为离散化为动作标记,并将其与具有强大开放世界理解能力的视觉语言模型(VLM)相结合,从而能够在单个自回归序列中对视觉、语言和动作进行联合建模,”研究人员写道。“通过使用二维边界框坐标来指导推理链,并应用强化学习来改进视点选择策略,我们仅使用少量真实世界数据,就将 VLM 的开放世界场景理解能力迁移到视觉语言动作(VLA)策略中。”
卓越的性能和潜在的未来应用
研究人员已在一系列室内实验中测试了他们提出的系统,评估了该系统获取更清晰图像并准确解读图像的能力。他们发现,该系统性能卓越,且无需依赖非常昂贵的传感器和摄像头。
“实验表明,我们的系统能够高效地在真实环境中执行指令场景,并通过指令驱动的旋转和缩放操作主动获取更准确的视觉信息,从而实现强大的环境感知能力。”研究人员写道。
EyeVLA引入了一种新型机器人视觉系统,该系统利用细节丰富、空间分布广的大规模具身数据,主动获取信息量极高的视觉观测结果,以支持后续的具身任务。
未来,该研究团队开发的类眼视觉系统有望得到进一步改进,并在更广泛的动态环境中进行测试。最终,该系统有望与其他机器人组件集成,并部署到实际应用场景中。
EyeVLA最终有望提升机器人在众多应用领域的性能,例如基础设施、仓库或公共场所的巡检,自然环境的监测以及高效完成家务。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





