中国研究人员发明新型多模态人工智能框架 为自动驾驶汽车带来类似人类的推理能力

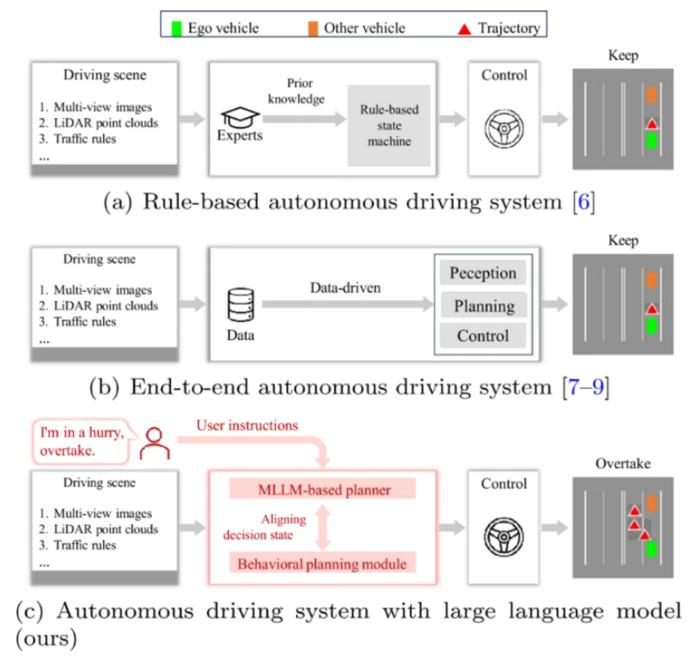
自动驾驶技术发展迅速,已从基于规则的系统发展到深度神经网络。然而,端到端模型仍然存在一些重大缺陷:它们通常缺乏对世界的认知,在罕见或模糊的场景下表现不佳,并且对其决策过程的解释能力有限。相比之下,大语言模型(LLM)擅长推理、理解上下文和解释复杂的指令。但是,LLM的输出是语言形式而非可执行指令,这使得将其与实际车辆控制系统集成变得困难。这些不足之处凸显了对一种框架的需求,该框架能够将多模态感知与基于既定驾驶逻辑的结构化、可执行的决策输出相结合。解决这些挑战需要深入研究如何将多模态推理与自动驾驶规划器相结合。
图片来源: 期刊《Visual Intelligence》
据外媒报道,上海交通大学、上海人工智能实验室、清华大学及合作机构的研究团队开发了一种用于闭环自动驾驶的多模态大型语言模型框架DriveMLM。相关研究成果已发表在期刊《Visual Intelligence》上(DOI: 10.1007/s44267-025-00095-w)。
DriveMLM集成了多视角摄像头图像、激光雷达点云、系统消息和用户指令,生成对齐的行为规划状态。这些状态可以直接输入到现有的运动规划模块,从而实现实时驾驶控制,同时生成对每个决策的自然语言解释。
DriveMLM解决了基于LLM的自动驾驶领域的一个核心挑战:如何将语言推理转化为可靠的控制行为。该框架将LLM的输出与模块化系统中使用的行为规划状态对齐,涵盖速度决策(保持、加速、减速、停止)和路径决策(跟随、左变道、右变道等)。
一个专门的多模态分词器将多视角时序图像、激光雷达数据、交通规则和用户指令处理成统一的令牌嵌入。然后,一个多模态LLM预测合适的决策状态并生成相应的解释,从而确保可解释性。
为了支持训练,该团队创建了一个大规模数据引擎,生成了跨越八个CARLA地图和30个挑战性场景的280小时驾驶数据,其中包括罕见的危及安全的关键事件。该流程自动标注速度和路径决策,并利用人工优化和基于GPT的增强技术生成丰富的解释性注释。
在CARLA Town05 Long基准测试的闭环评估中,DriveMLM的驾驶得分达到76.1分,比Apollo基线高出4.7分,并且在所有对比系统中实现了最高的每干预里程数(0.96)。DriveMLM还展现出强大的开环决策准确性、改进的解释质量以及在自然语言指导下的稳健性能——例如在不同的交通条件下避让紧急车辆或解释用户指令(例如“超车”)。
研究团队指出:“我们的研究表明,LLM一旦与结构化决策状态对齐,就可以成为自动驾驶汽车强大的行为规划器。DriveMLM超越了简单的规则遵循。它能够理解复杂的场景,对运动进行推理,并以自然语言解释其决策——这些能力对于安全和公众信任至关重要。通过将感知、规划和人类指令整合到一个统一的框架中,DriveMLM为下一代自动驾驶系统提供了一个充满希望的发展方向。”
DriveMLM展示了多模态大型语言模型如何增强自动驾驶的透明度、灵活性和安全性。其即插即用的设计使其能够无缝集成到Apollo或Autopilot等现有系统中,从而在无需进行重大架构更改的情况下改进决策制定。其理解自然语言指令的能力拓展了交互式驾驶辅助和个性化车载人工智能副驾驶的可能性。更广泛地说,DriveMLM指明了一条通往基于推理的自动驾驶系统的道路,该系统能够理解复杂的环境、预测风险并解释其行为——这些都是在实际交通网络中部署值得信赖的人工智能的关键能力。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。