
UNIST开发全新框架明确数据 有助于实现自动驾驶汽车高可靠性

人工智能(AI)系统(例如即使在暴风雪中也能保持行驶路线的自动驾驶汽车,或能够通过低分辨率图像诊断癌症的医疗人工智能)的高可靠性很大程度上取决于模型的鲁棒性。虽然数据增强长期以来一直是提高这种鲁棒性的常用技术,但其最佳工作条件一直不甚明了——直到现在。
图片来源:蔚山科学技术院
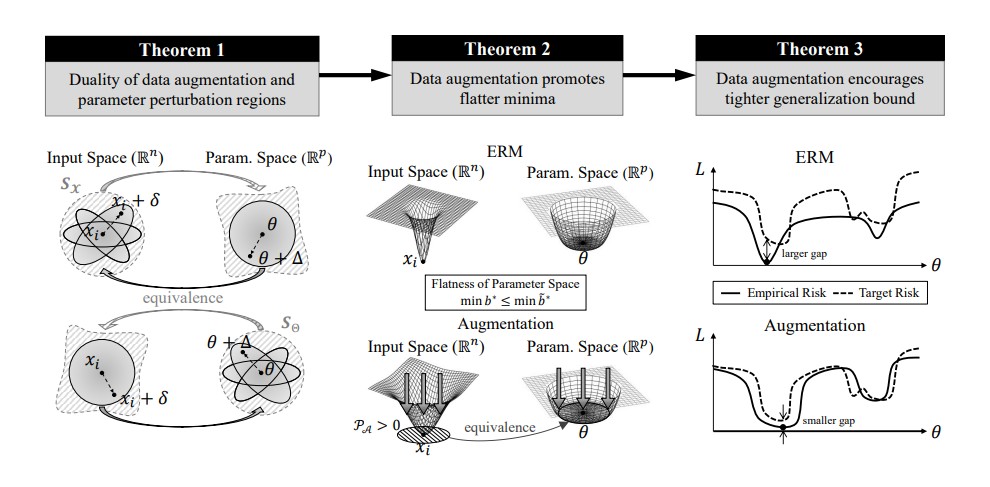
据外媒报道,韩国蔚山科学技术院(UNIST)人工智能研究生院(Graduate School of Artificial Intelligence)的Sung Whan Yoon教授及其研究团队开发了一种数学框架,能够精确解释数据增强何时以及如何提高模型应对数据分布意外变化的能力。这一突破为更系统、更有效地设计数据增强策略铺平了道路,显著加快了人工智能的开发速度。在此基础上,该团队严格证明了数据增强能够提升模型鲁棒性的必要条件。
深度学习模型在面对与训练数据略有不同的数据时,往往会遇到困难,导致性能急剧下降。数据增强,即创建训练数据的修改版本,有助于解决这个问题。然而,选择最有效的数据转换方法历来是一个反复试验的过程。
研究团队发现了一种名为近端支持增强(proximal-support augmentation,PSA)的特定条件,该条件可确保增强后的数据密集地覆盖原始样本周围的空间。当满足此条件时,模型损失函数的最小值会更加平坦、稳定。平坦的最小值通常与更高的鲁棒性相关,使模型对偏移或攻击的敏感性更低。
实验结果证实,满足PSA条件的增强策略在提高各种基准测试中的鲁棒性方面优于其他策略。
Sung Whan Yoon教授解释说:“这项研究为设计数据增强方法提供了坚实的科学基础。它将有助于在数据可能意外变化的环境中构建更可靠的人工智能系统,例如自动驾驶汽车、医学成像和制造检测。”
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。




