
阿米尔卡比尔理工大学提出逆强化学习方法Irl-Dal 可实现更安全的自动驾驶

据外媒报道,来自阿米尔卡比尔理工大学电气工程系的研究人员Seyed Ahmad Hosseini Miangoleh、Amin Jalal Aghdasian和Farzaneh Abdollahi提出逆强化学习方法IRL-DAL,结合了专家模仿、自适应规划和一种新型安全监控器。这项工作意义重大,因为它在模拟环境中实现了96%的成功率,同时显著降低了碰撞事故,为自主导航树立了新的标杆,并有望在充满挑战且难以预测的真实世界场景中展现出更稳健的性能。
图片来源:https://arxiv.org/abs/2601.23266
基于扩散的逆强化学习在提升自动驾驶安全性方面展现出令人瞩目的成果
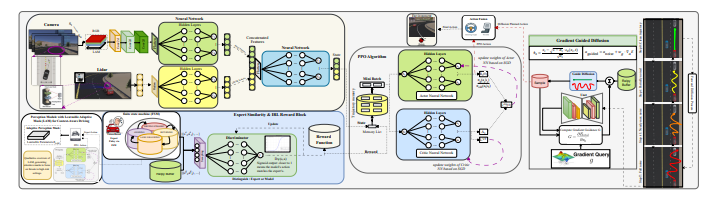
该新型逆强化学习框架旨在显著提升自动驾驶车辆的导航性能。该研究引入了一种基于扩散的自适应前瞻规划器,旨在实现更安全、更稳健的驾驶能力。训练首先通过模仿学习专家级有限状态机控制器,为后续学习阶段奠定稳定的基础。
随后,将环境因素与逆强化学习判别器信号相结合,使车辆的动作与期望的专家级目标保持一致。最后,采用混合奖励系统实现强化学习,该系统结合了扩散环境反馈和来自逆强化学习过程的目标奖励。
条件扩散模型充当安全监控器,精心规划安全路径,以保持车道位置、避开障碍物并确保车辆平稳行驶。至关重要的是,可学习的自适应掩码能够根据车速和附近危险情况动态调整视觉注意力,从而提升感知系统的性能。
在初始模仿阶段之后,驾驶策略使用近端策略优化(一种用于策略改进的复杂算法)进行微调。在Webots模拟器中进行了大量的训练,采用两阶段课程逐步挑战自主智能体。
该团队在导航任务中取得了惊人的96%成功率,同时将碰撞率降低至每千步仅0.05次,为安全自动驾驶性能树立了新的标杆。通过实施这一创新方法,该智能体不仅展现了出色的车道保持能力,还能熟练地应对各种危险状况,从而显著提升了整体鲁棒性。
研究人员已将代码公开,以促进该关键领域的进一步研究和开发。这项工作为创建能够在复杂动态环境中导航且安全性和可靠性堪比人类驾驶员的自主系统开辟了新的途径。
该研究首先利用有限状态机(FSM)控制器进行模仿训练,为后续学习奠定稳定的基础。随后,将环境因素与IRL判别器信号相结合,使智能体的行为与专家驾驶目标保持一致。
接下来,研究人员采用混合奖励系统进行强化学习,该系统结合了环境反馈和目标IRL奖励,以优化策略。条件规划器作为安全监督器,通过保持车道位置、避开障碍物和促进车辆平稳行驶,确保路径规划的安全。
研究人员设计了一种可学习自适应掩码(LAM)来提升感知能力,它能够根据车速和附近危险情况动态调整视觉注意力。在基于有限状态机(FSM)的模仿之后,该策略利用近端策略优化(PPO)进行微调,并在Webots模拟器中采用两阶段训练方案。
该方法不仅使智能体能够保持车道行驶,还能以专家级水平有效应对不安全状况,从而显著提升整体鲁棒性。
实验首先利用有限状态机(FSM)控制器进行模仿学习,为后续的强化学习奠定稳定的基础。研究团队通过两阶段课程评估系统性能,该课程结合了环境反馈和目标导向的逆强化学习奖励。
数据显示,平均奖励显著提升,从基线PPO和均匀采样下的85.2提升至采用完整IRL-DAL框架后的180.7。这一16%的提升伴随着碰撞次数的减少,从每1000步0.63次降至0.05次。该系统利用64×64大小的4通道视觉张量,结合180光束激光雷达扫描,构建全面的环境感知。
进一步分析表明,引入有限状态机(FSM)回放缓冲区使平均奖励提升了41%,而扩散规划器则贡献了29%的提升。可学习自适应掩码(LAM)和安全感知能量控制器(SAEC)进一步优化了性能,最终实现了2.45米的平均位移误差(ADE)和5.1米的最终位移误差(FDE)。
测试证明,该系统能够以专家级水平有效应对不安全状况,增强了鲁棒性,并实现了更平顺的变道和碰撞规避。算法1详细描述了集成的训练流程,其中包括FSM感知回放、行为克隆、生成对抗模仿学习、近端策略优化、基于扩散的自适应前瞻规划器和安全感知能量控制器。
研究人员表示,目前的评估仅限于Webots模拟器,未来的工作可以探索真实世界测试和更复杂的环境。进一步的研究方向包括研究LAM对不同传感器模式的泛化能力,以及扩展该框架以处理更复杂的交通交互。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





