宾夕法尼亚大学开发AI音频编辑器SmartDJ 只需简单指令即可重塑音频体验

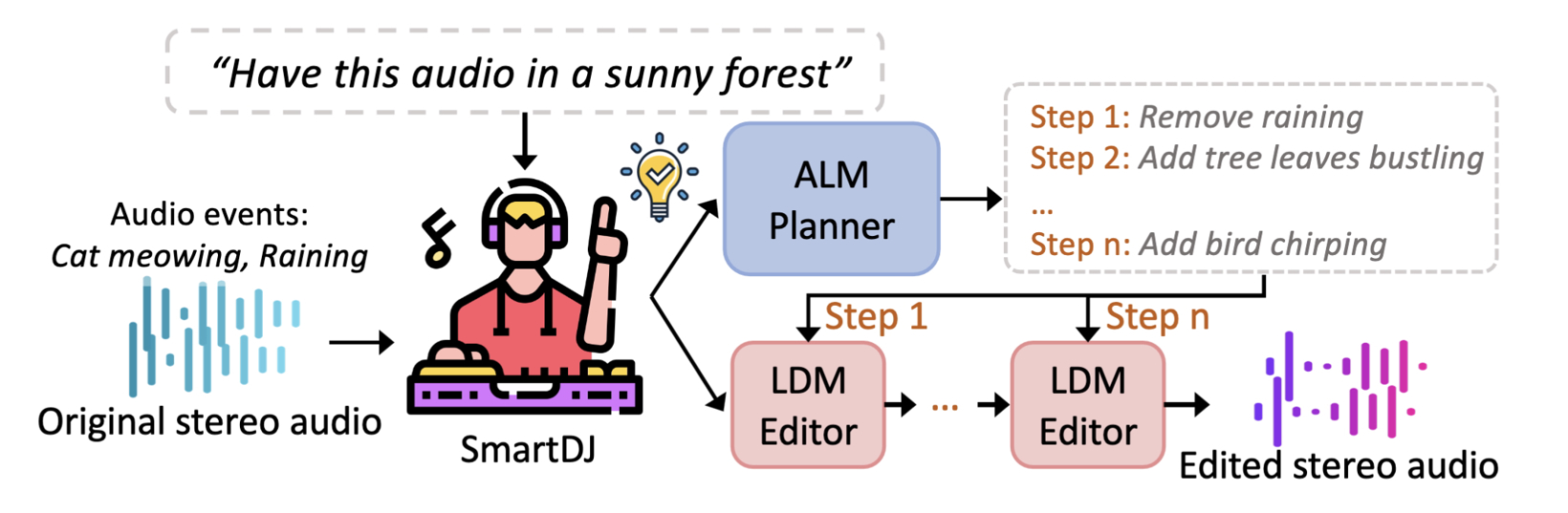
据外媒报道,宾夕法尼亚大学(University of Pennsylvania,Penn)的工程师开发出人工智能(AI)音频编辑器SmartDJ,用户只需使用日常语言的简单指令即可修改沉浸式音频环境,其潜在应用领域包括虚拟现实、增强现实、游戏和声音设计。SmartDJ无需用户指定具体的编辑内容,即可响应诸如“让这里听起来像繁忙的办公室”之类的高级指令,然后规划并执行实现该效果所需的步骤。
图片来源:WAVES Lab
该系统解决了早期AI音频编辑工具的两大局限性:首先,大多数先前的系统更适用于僵化的、模板式的命令,需要用户识别要添加或删除的声音;其次,这些工具通常处理的是单声道或“单轨”音频,失去了沉浸式音频体验所必需的空间线索。
相比之下,SmartDJ能够理解高级指令,并且专为立体声音频设计,因此能够进行编辑,从而更好地保留或重塑场景的空间结构。
更重要的是,该系统具有可解释性:用户可以看到SmartDJ执行的每一步操作。例如,如果用户输入“让这里听起来像繁忙的办公室”,SmartDJ可能会生成类似“在右侧添加3dB的电话铃声”这样的指令。用户可以修改、删除或添加单个步骤,从而更好地控制最终结果。
计算机与信息科学系(CIS)助理教授Mingmin Zhao表示:“使用SmartDJ,用户可以用自然语言描述他们想要的结果,系统会自动找出实现的方法。这证明AI可以帮助人们使用简单的语言以直观的方式编辑音频。”
语言模型与扩散模型的结合
AI音频编辑面临的核心挑战之一是理解用户请求和生成声音通常由不同类型的AI系统处理。电子与系统工程系(ESE)博士生、该研究的第一作者Zitong Lan说道:“我们使用语言模型来处理文本,使用扩散模型来编辑声音。”
其中的区别在于每个系统接受训练的目的不同。语言模型——与聊天机器人使用的技术相同——学习词语中的模式,帮助它们理解用户的意图并生成相应的文本。扩散模型则旨在通过将噪声逐渐塑造成连贯的信号来生成媒体数据。
为了弥合这一差距,研究团队在编辑流程中引入了音频语言模型(ALM)。ALM经过声音和文本的双重训练,能够分析原始音频以及用户的提示,并将提示分解成一系列更小的编辑操作,例如添加、删除或重新定位声音。随后,扩散模型会逐步执行这些操作,从而使SmartDJ能够同时理解语言和编辑音频。
本质上,语言模型扮演着制作人的角色,决定音景应该如何变化;而扩散模型则像录音室乐手一样,将这些指令转化为音频。CIS博士生、该研究的合著者Yiduo Hao表示:“语言模型为系统提供指令,扩散模型则负责执行这些指令。”
SmartDJ训练
为了学习如何将广泛的用户请求转化为循序渐进的音频编辑步骤,SmartDJ需要一些训练,这些训练能够同时包含三个要素:高级指令、执行该指令所需的编辑操作序列,以及每次修改前后的音频。
遗憾的是,这种训练数据并不存在。Lan说道:“解决这个问题需要一种非常特殊的数据集,它必须同时捕捉目标、步骤和结果。”
因此,团队决定自行构建。研究人员利用公开的音频库,创建了一个流程,该流程使用大型语言模型生成高级编辑提示以及执行这些提示所需的中间步骤,同时通过音频信号处理生成相应的编辑输出。Hao表示:“为了让其正常工作,我们不能只向模型展示输入和输出,我们还必须向它展示中间的推理过程。”
迈向更便捷的音频编辑
为了测试SmartDJ,研究人员将其与早期的音频编辑系统进行了比较,发现SmartDJ能够产生更逼真、更精准的音频效果。在定量评估和用户研究中,SmartDJ在音频质量、结果与用户指令的匹配度以及声音在空间中的逼真度等指标上均优于以往的方法。
研究人员认为SmartDJ在虚拟现实、增强现实、游戏、声音设计、虚拟会议和其他交互式媒体领域具有潜在的应用价值,用户可以在这些领域重塑音频环境,而无需手动指定每一个细节。
研究人员最终的目标是让音频编辑更加便捷,让任何具有创意的人都能编辑音景。Zhao表示:“对于文本和图像等其他媒体数据,用户已经可以使用AI来发出高级编辑请求,SmartDJ 为音频领域开启了类似的可能,让更多人能够更轻松地将他们的想法变为现实。”
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。