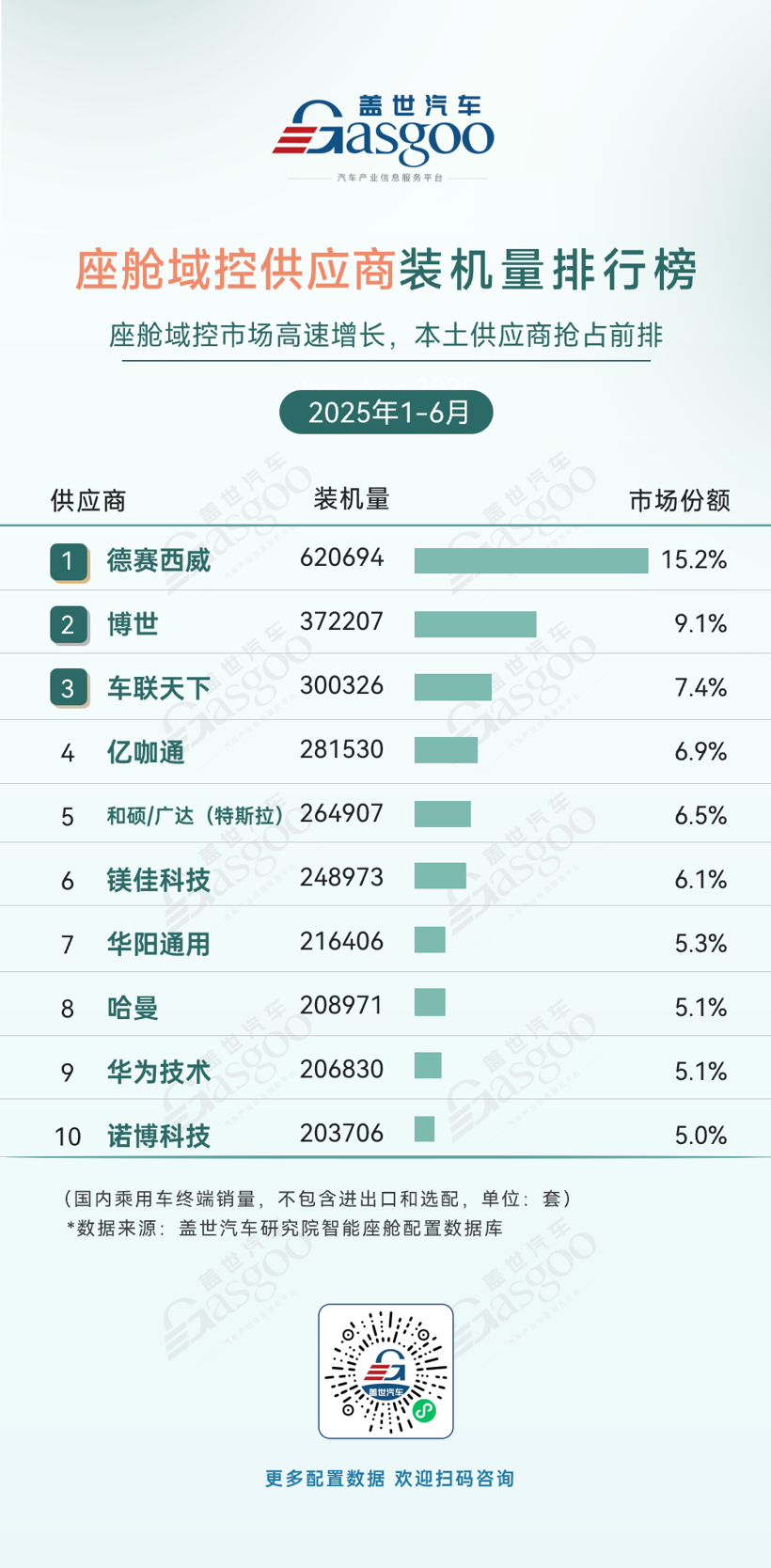
研究人员利用LLM创建语言指纹 或助力自动驾驶汽车做出更好的决策

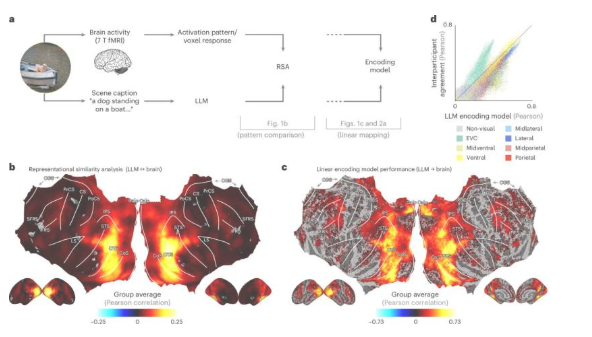
当我们观察世界时,大脑不仅能识别“一只狗”或“一辆车”这类物体,更能理解其中的深层含义,例如正在发生什么事情,在哪里发生,以及万物间的关联。然而,研究人员一直未找到很好的方法来测量这种丰富而复杂的理解能力。
(图片来源:Nature Machine Intelligence)
据外媒报道,蒙特利尔大学(University of Minnesota)心理学副教授Ian Charest探讨如何使用大语言模型(LLM)来解决这个问题。参与研究的还包括明尼苏达大学(University of Minnesota)、德国奥斯纳布吕克大学(University of Osnabrück)和柏林自由大学(Frei Universität Berlin)的研究人员。相关论文发表于期刊《Nature Machine Intelligence》。
Charest表示:“通过将自然场景描述输入这些LLM,即ChatGPT等工具背后的同类型人工智能,我们创建了一种“基于语言的指纹”来表示场景的含义。”
出乎意料的是,这些语言指纹与人们在核磁共振扫描仪中观察相同场景时记录的大脑活动模式高度吻合,例如群童嬉戏或都市天际线等画面。Charest表示:“举例来说,借助LLM,我们只需一句话就能解码受试者刚刚感知的视觉场景。基于LLM编码的语义表征,我们还能精确预测大脑对食物、地点或含有人脸的场景会作出何种反应。”
研究人员进一步训练人工神经网络来接收图像,并预测这些LLM指纹。结果发现,这些网络在匹配大脑反应方面,比目前许多最先进的AI视觉模型表现更好。更何况现有模型的训练数据还少得多。这些“人工神经网络”的概念得到了奥斯纳布吕克大学机器学习教授Tim Kietzmann及其团队的支持。该研究的第一作者是柏林自由大学的Adrien Doerig教授。
目前,Charest正在持续进行相关研究。他表示:“当前研究成果表明,人脑对复杂视觉场景的表征方式,可能与现代语言模型理解文本的机制高度相似。”
这项研究为解码思想、改进脑机接口、构建更智能的AI系统提供了新的可能性。有一天,人们可能构想出更好的视觉计算模型,从而支持自动驾驶汽车做出更好的决策。未来,这些新技术还可能用于开发视觉假体,为视力严重受损的人群提供帮助。无论如何,这在了解人类大脑如何理解视觉世界的意义方面向前迈出了一步。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。