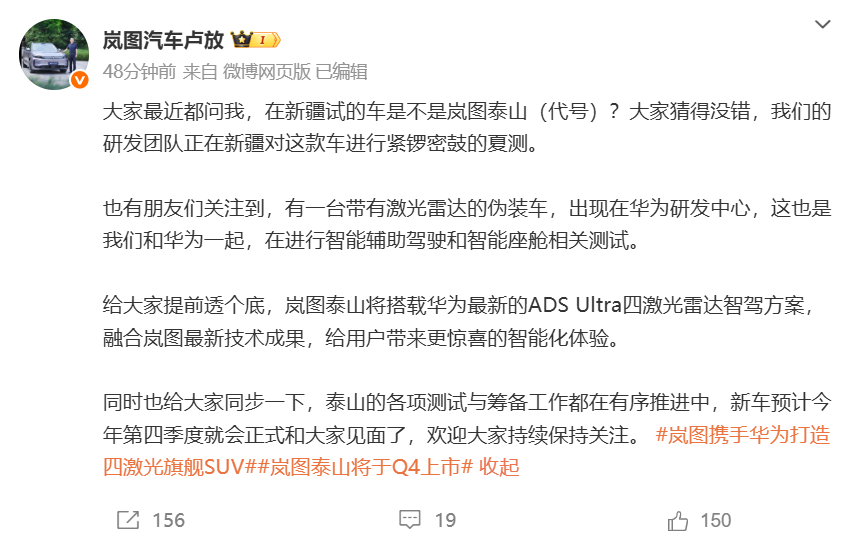
美国OAK分类法可帮助AI动态解读同一图像 或有助于机器人技术等应用

据外媒报道,美国密歇根大学(U-M)研发了一种名为开放即兴分类(open ad-hoc categorization,OAK)的新方法,可帮助人工智能(AI)系统根据不同的分类情境,动态地对同一图像进行不同的解读,而非采用固定的视觉解读方式。

OAK方法解读图像(图片来源:密歇根大学)
密歇根大学计算机科学与工程系教授兼该研究的资深作者Stella Yu表示:“当人们谈及利用AI进行图像分类,通常假设每张图片都有唯一且客观的含义。然而,我们的研究表明,一张图片可以根据任务、情境或目标,从多个角度进行审视。就像人类不会视图像为静态信息,而是根据自身需求调整其含义,AI也可以灵活地解读图像,根据情境和目标进行相应的调整。”
以往的AI分类方法采用的是诸如“椅子”、“汽车”或“狗”等固定、僵化的分类,无法适应不同的用途或情境。OAK则可以根据期望的情境,对同一图片做出不同的评估。例如,一张人在喝水的图片,可以归类为“喝水”这一动作,“在商店”这一地点,或者“开心”这一情绪。
该研究团队通过扩展OpenAI的CLIP(一种基础的视觉语言AI模型,能够学习将图像与文字描述关联起来)来构建其模型。之后,研究团队添加了上下文标记,此类标记相当于为AI模型定制的一组指令,从有标签和无标签的数据中学习而来,与图像数据一起输入系统,以针对不同的情境塑造视觉特征处理。最终,该模型能够自然地聚焦于相关的图像区域,如识别动作时聚焦于手部区域,在描述地点时聚焦于背景,而无需明确告知其应关注何处。
重要的是,新型上下文标记会经过训练,而原始的CLIP系统保持不变,从而使该模型能够适应不同的用途,而不会丢失现有的知识。
“我们惊讶地发现,该系统仅需少量标记示例和有限的上下文信息,便能够高效地学习如何恰当地分配注意力,并对数据进行有条理的组织。”密歇根大学计算机科学与工程专业博士生、该研究的主要作者Zilin Wang表示。
此外,OAK能够识别在训练过程中未曾接触过的新型类别。例如,在被要求识别图像中,适合在旧货市场出售的物品时,即使只向其展示了鞋子的示例,该系统也能够找到诸如行李箱或帽子之类的物品。
OAK采用自上而下与自下而上相结合的方法来识别新类别。其中,自上而下的语义引导机制利用语言知识生成潜在的新类别。例如,如果你知道鞋子可以在旧货市场中出售,系统便会据此扩展,提出帽子也能在旧货市场中出售,即便在训练过程中未曾见过帽子的示例。
除了语言知识外,OAK采用了一种自下而上的视觉聚类方法,能够从未标记的视觉数据中识别出模式。针对当前任务,该系统可能会在大量未标注的图像中频繁观察到行李箱这一对象。因此,即使没有任何行李箱被标注为有效物品,其也能发现一个适用于旧货市场的新相关类别。
研究人员在训练过程中,让上述两种方法协同工作。例如,帽子等语义提议会让视觉系统去寻找帽子。如果找到了,就确认其为一个有效的新类别。另一方面,显著的视觉聚类则采用CLIP现有的图像-文本知识来帮助确认如何可以称为聚类。
该研究团队在两组图像数据集——Stanford和Clevr-4上测试了OAK模型,并将其性能与两组基线模型——拥有扩展词汇量的CLIP和广义类别发现(GCD)方法进行对比。
OAK在多个分类任务中的准确性和概念发现均达到了最先进水平。特别值得关注的是,在Stanford数据集的情绪识别任务中,OAK的创新准确率达到了87.4%,相较于CLIP和GCD方法,高出50%以上。
虽然所有的方法均能生成显著图,OAK的显著图通过从数据中学习而非依赖编程生成,能够根据每个上下文信息聚焦图像的正确部分,从而在保持灵活性的同时,提供可解释的结果。
展望未来,OAK的情境化方法将有助于机器人技术等应用领域,在此类应用中,系统需要根据当前的任务,以不同的方式感知相同的环境。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。