Penn State发明新型人工智能系统 助力解释激光焊接缺陷

人工智能驱动的大型语言模型(LLM)需要在海量数据集上进行训练才能做出准确的预测——但如果研究人员没有足够的正确类型的数据怎么办?
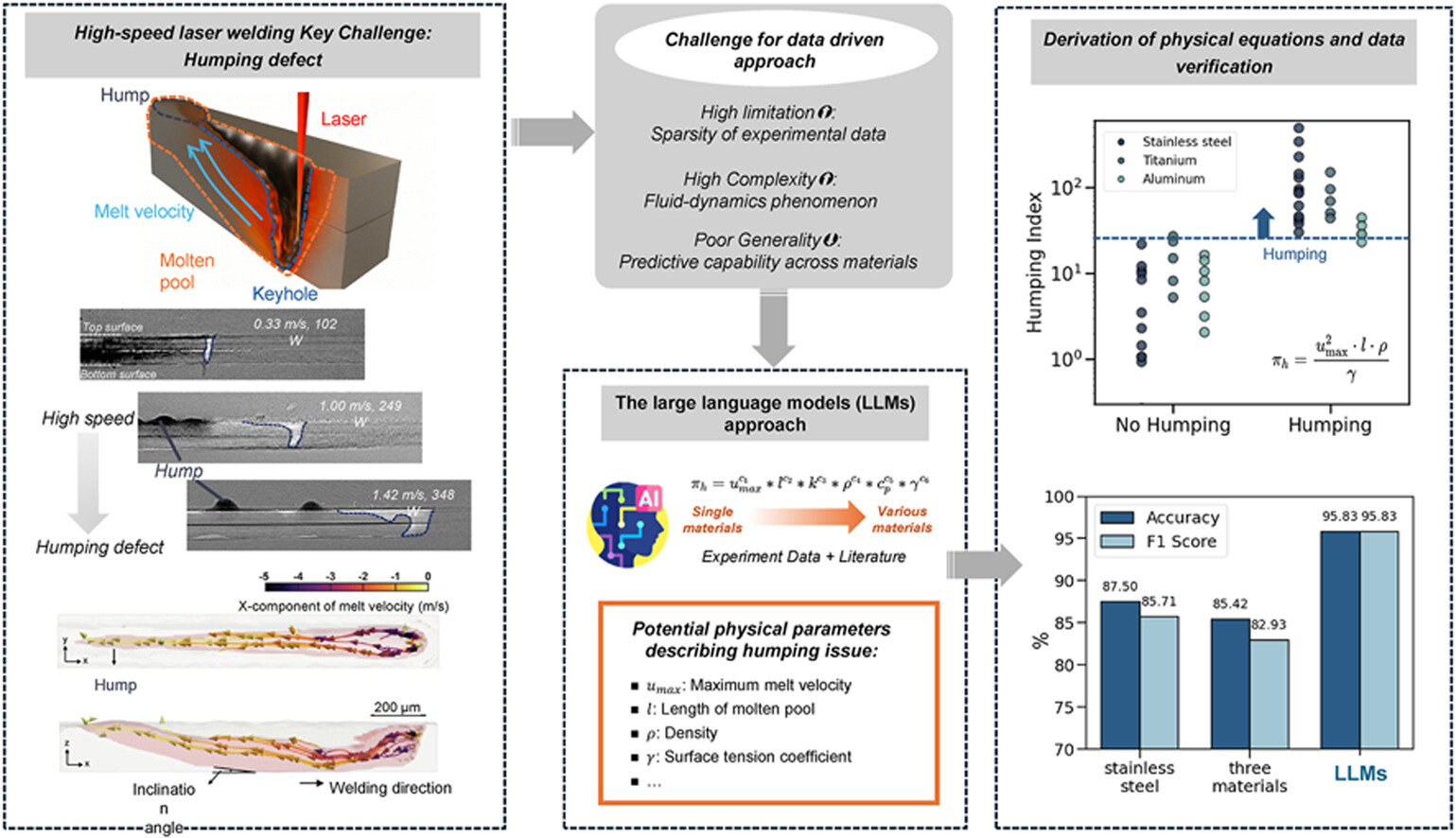
据外媒报道,宾夕法尼亚州立大学(Pennsylvania State University,Penn State)的研究团队最近开发了一个集成框架,该框架使用最少的新实验数据来识别现有科学文献中的相关信息。通过结合现有研究和他们自己的实验信息,这个由LLM驱动的框架可以推导出数值方程,从而准确预测高速激光焊接中的物理现象。高速激光焊接是一种能够对电动汽车燃料电池等物体进行高精度焊接的制造技术。
图片来源: 期刊《the International Journal of Machine Tools and Manufacture》
研究人员表示,利用新方法可以开始优化焊接技术,而这种技术通常很容易出现技术故障。相关研究论文发表在期刊《the International Journal of Machine Tools and Manufacture》十月刊上。
据该论文的共同作者、工业与制造工程(IME)博士生Zhengxiao Yu介绍,传统的方程式构建方法对研究人员来说非常耗时,而且需要大量的现有数值数据。为了准确地构建方程式,研究人员要么必须从自己的实验中生成1000多个数据点,要么必须查阅并解读其他研究人员先前研究中的数据点。
“有了我们的模型,我们只需输入文献数据,就能显著加快这一过程,”Yu说道。
数值方程使研究人员能够更好地理解各种参数之间的联系,从而深入了解焊接过程中某些物理反应出现的原因和时间。
据材料科学与工程博士生、论文合著者Zen-Hao Lai介绍,该LLM可以帮助解释的最常见现象之一是“驼峰”——一种常见的激光焊接缺陷,当金属焊接速度过快时就会出现。详细描述驼峰误差相关具体参数的方程式可以帮助研究人员在未来的焊接中解决这个问题。
使用方程式还能让团队在预测新焊缝的物理特性时有效地整合先前实验的数据,即使旧焊缝的物理特性(例如金属类型或焊接系统的速度)并不完全相同。
IME和工程科学与力学教授Jingjing Li表示,挑战在于先前实验的数据通常仅以文本形式提供,这意味着研究人员必须逐一梳理多篇论文才能识别数据,然后将其转换为正确的格式。
“我们拥有足够的现有数据,但其中大部分是基于文本而非数值数据,而且高度实验性,这意味着很难推广到新的焊接工艺,”Jingjing Li解释说。“传统上,如果没有数值数据,我们就无法建立方程式,但LLM模型的应用使我们能够做到这一点。”
该团队使用了总共48个数据集来开发他们的框架,其中5个来自他们自己的实验,43个来自现有研究。该团队利用实验数据(包括金属类型和驼峰频率)来构建代表特定变量及其关系的候选方程式。然后,研究人员制定了一个评估标准,供LLM处理现有科学文献时使用。
LLM可以识别相关信息,转换正确的数据,并推荐最有可能描述不同物理参数如何影响焊缝质量或焊缝是否会出现驼峰的方程式。
虽然LLM并未完全自动化选择方程式的过程,但Jingjing Li解释说,它比以前的方法更高效、更具有通用性。使用该框架,大约一分钟内即可生成10个方程式——比使用传统方法创建一个方程式需要数小时的研究效率高得多。然后,研究人员根据制定的评分标准对方程式进行评分和排序,并使用得分最高的方程式。
“我们使用熔体速度、热导率和密度等焊接物理参数来确定如何应用该方程,” Jingjing Li说道。“这仍然需要研究人员具备大量的领域知识,但可以在此基础上进行改进,并使我们的方程在不同材料和物理特性之间保持标准化。”
该团队计划继续优化他们的框架,目标是将LLM模型有效地应用于制造业的不同应用领域。
“我们这项工作的真正目的是以一种新颖的方式将现有的LLM模型应用于制造领域,”Yu说道。“结合这个框架,我们可以优化增材制造,以及激光焊接以外的其他制造应用。”
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。