东京理科大学发明近似领域遗忘 实现更安全、更可控的视觉语言模型

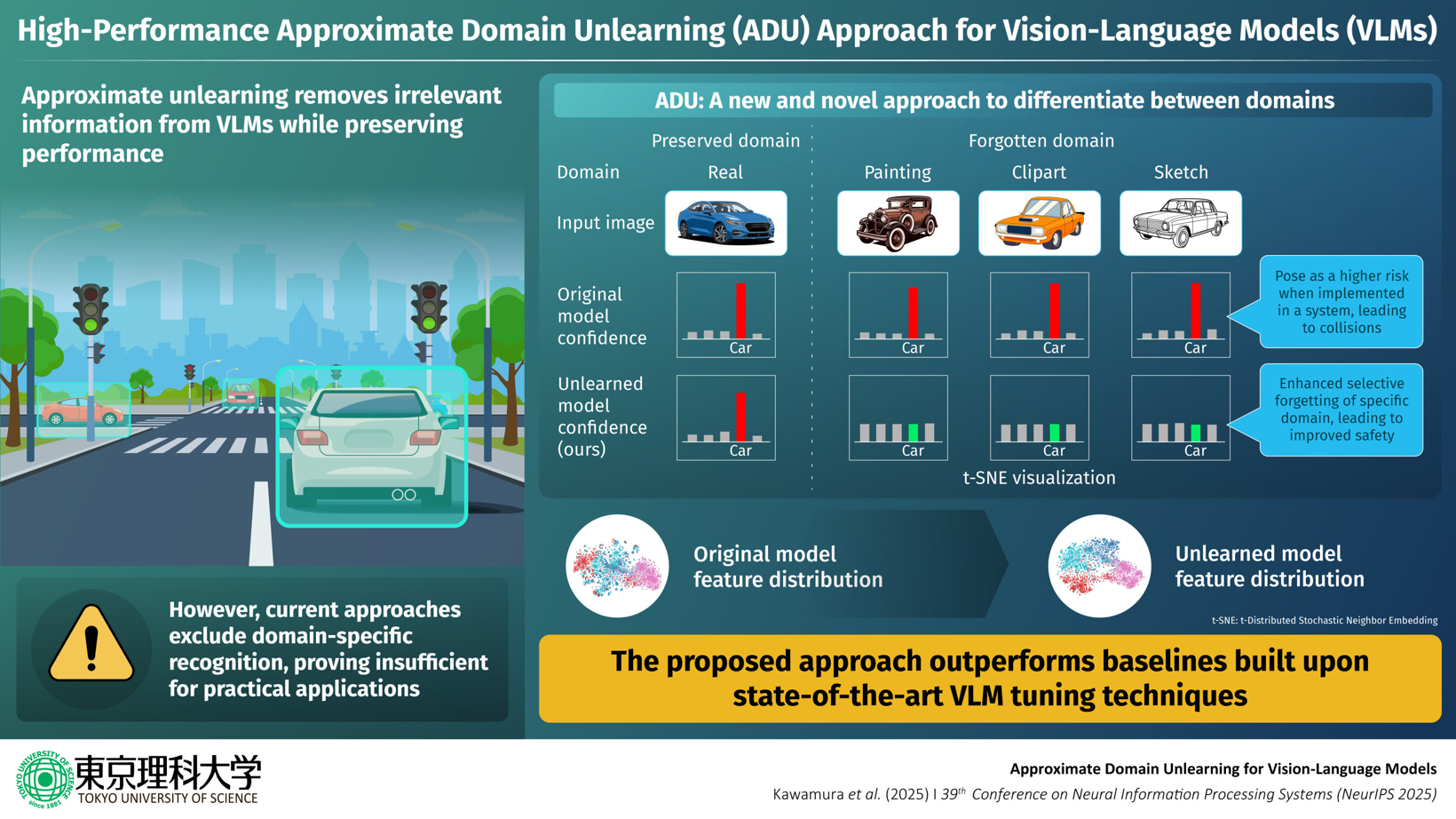
视觉语言模型(VLM)是现代人工智能(AI)的核心技术,可用于表示不同形式的表达或学习内容,例如照片、插图和草图。它具有很强的泛化能力,使其能够准确识别特定领域内图像中的物体。然而,这种泛化能力也存在风险。例如,VLM 可以将真实车辆和插图车辆都识别为“车辆”。
如果将这种模型应用于实际系统中,则存在将路边广告中的插图车辆误认为真实车辆,从而导致严重交通事故的风险。为了将安全可靠的人工智能应用于实际,必须建立能够根据应用场景适当控制学习知识的技术。
图片来源: 东京理科大学
据外媒报道,针对这一问题,由日本东京理科大学(Tokyo University of Science)副教授Go Irie领导的研究团队提出了近似域遗忘(approximate domain unlearning,ADU)算法。该算法允许VLM“遗忘”特定域,使其无法识别这些域。例如,根据研究结果,该算法能够高精度地识别现实生活中的车辆。
这项创新性研究由东京理科大学的Kodai Kawamura和Yuta Goto、日本产业技术综合研究所(AIST)的Rintaro Yanagi博士以及AIST和牛津大学的Hirokatsu Kataoka博士共同撰写。该研究成果也已发表在arXiv预印本服务器上。
“人工智能技术长期以来一直致力于在所有领域内精确识别物体,这体现在数十年来对领域自适应和领域泛化的研究上,”Irie教授解释道。“虽然这种通用性仍然很重要,但具有卓越领域泛化能力的VLM的出现,让我们意识到这一假设本身值得重新审视。正是基于这种想法,我们构思了ADU——一种允许模型在必要时选择性遗忘特定领域的新方法。”
值得注意的是,技术难点在于VLM内部无法区分各个领域。由于不同领域在特征空间中存在重叠,因此很难仅选择并遗忘特定领域。
因此,本研究团队引入了一种名为域解耦损失(Domain Disentangling Loss)的方法,该方法能够促进特征空间中不同域之间的分离,并捕捉每幅图像中不同域的特征。
此外,通过引入实例提示生成器,所提出的算法在降低不必要域识别精度的同时,最大限度地减少了对这些域的需求。这使得人工智能能够灵活配置以适应各种实际场景,并实现以前无法实现的灵活知识控制,例如在保持功能性的同时,避免识别插图中的汽车。
有趣的是,ADU为风险管理引入了一个全新的视角。虽然人工智能风险管理的概念由来已久,但现代人工智能模型的泛化能力有时反而会带来新的风险。这项研究提出了一种构建人工智能的框架,该框架可以根据不同的使用场景进行灵活配置,从而确保安全性和适应性。
“随着人工智能性能的日益精进,为了促进可持续的工业应用,必须使其适应实际场景。我们相信,我们开发的这套系统能够让我们自由控制各项功能,从而为世界提供安全可靠的人工智能技术。”Irie教授总结道。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。